BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
介绍
BERT 单词表示的意思是Bidirectional Encoder Representations from Transformers。
BERT 的双向编码真实意思是与 GPT 不同,当前单词不仅能看到前面输入的句子,还能看到后面的句子,也就是没有用 Mask 的 attention 注意力。那么他的结构就与 Transformer 的 encoder 部分一模一样。所以 BERT 的预训练模型不是一个句子生成模型,而是一个句子的编码特征模型,它专注于理解和表示文本,而不是生成文本。
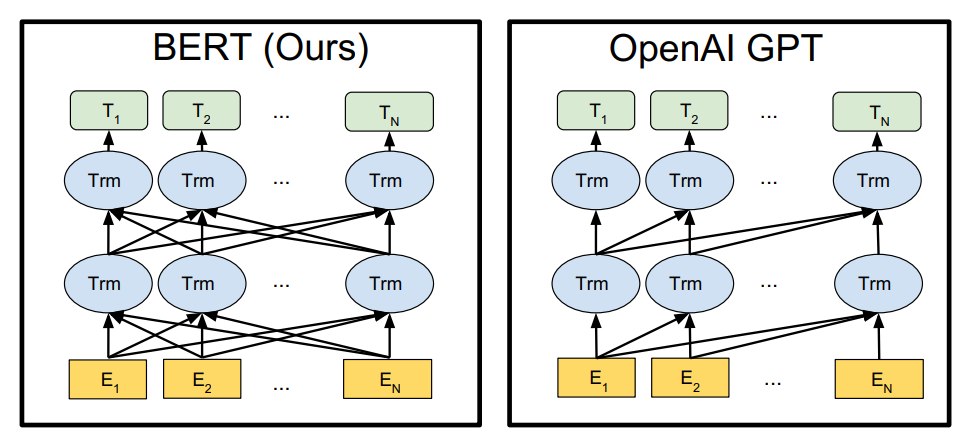
模型结构
Token 输入
为了让 BERT 能够处理各种下游任务,BERT 的输入表示可以清楚地表示单个句子或一对句子(例如“问题,答案”对),并将它们作为一个 token 序列输入给模型。跟 GPT 的方法相同,将句子进行拼接。
BERT 模型的输入嵌入(input embeddings)是由以下三部分相加得到的:
- Token Embeddings(词嵌入):每个单词或词片段的表示。它为每个输入的词提供一个向量表示。
- Segmentation Embeddings(分段嵌入):用于区分句子 A 和句子 B 的嵌入。在 BERT 的句子对任务中,句子 A 和句子 B 会分别赋予不同的分段嵌入,以让模型区分它们。
- Position Embeddings(位置嵌入):用于表示每个词在序列中的位置。因为 BERT 没有像 RNN 那样的顺序处理机制,位置嵌入帮助模型理解输入中词的相对顺序。
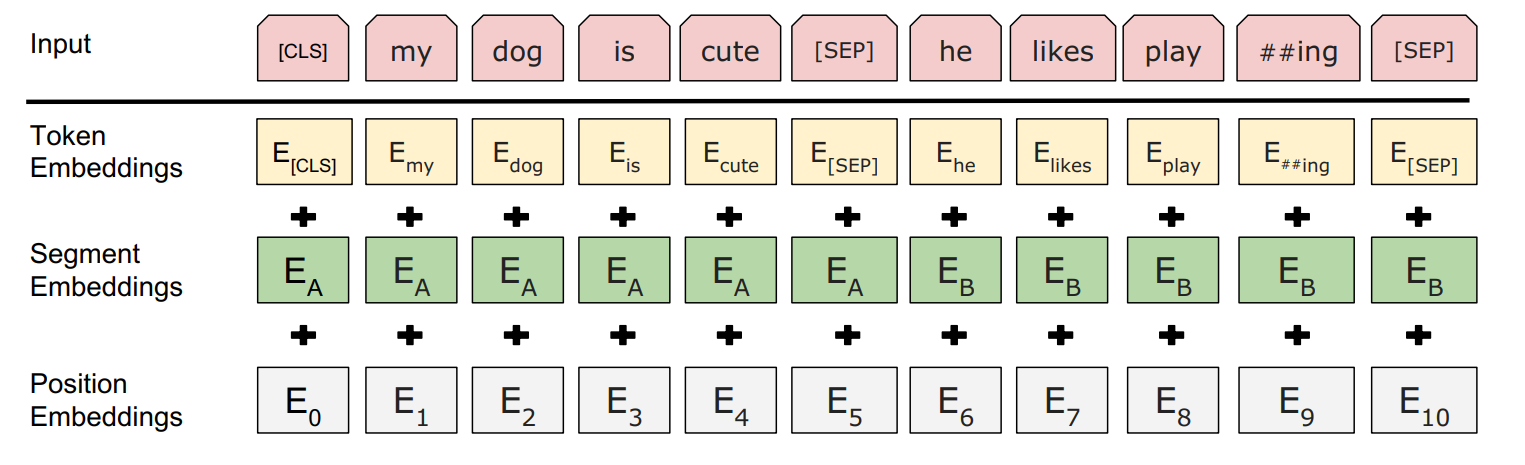
BERT 的输入嵌入是这三种嵌入的总和,它们共同帮助模型理解单词的语义、句子之间的区别以及词在句子中的位置。
模型任务
分类任务
分类任务中如何使用特殊的标记和嵌入。
特殊标记 [CLS]:
- 每个输入序列的第一个 token 始终是特殊的分类标记
[CLS]。 - 该标记的最终隐藏状态(hidden state)用于表示整个序列的汇总特征,主要用于分类任务,用
[CLS]的最终表征层输出作为分类特征。
句子对的处理:
- 在两个句子之间插入一个特殊的
[SEP]标记,起到分隔作用,最后一个句子也需要加入[SEP]。 - 为每个 token 添加一个学习到的嵌入,标识该 token 属于句子 A 还是句子 B。
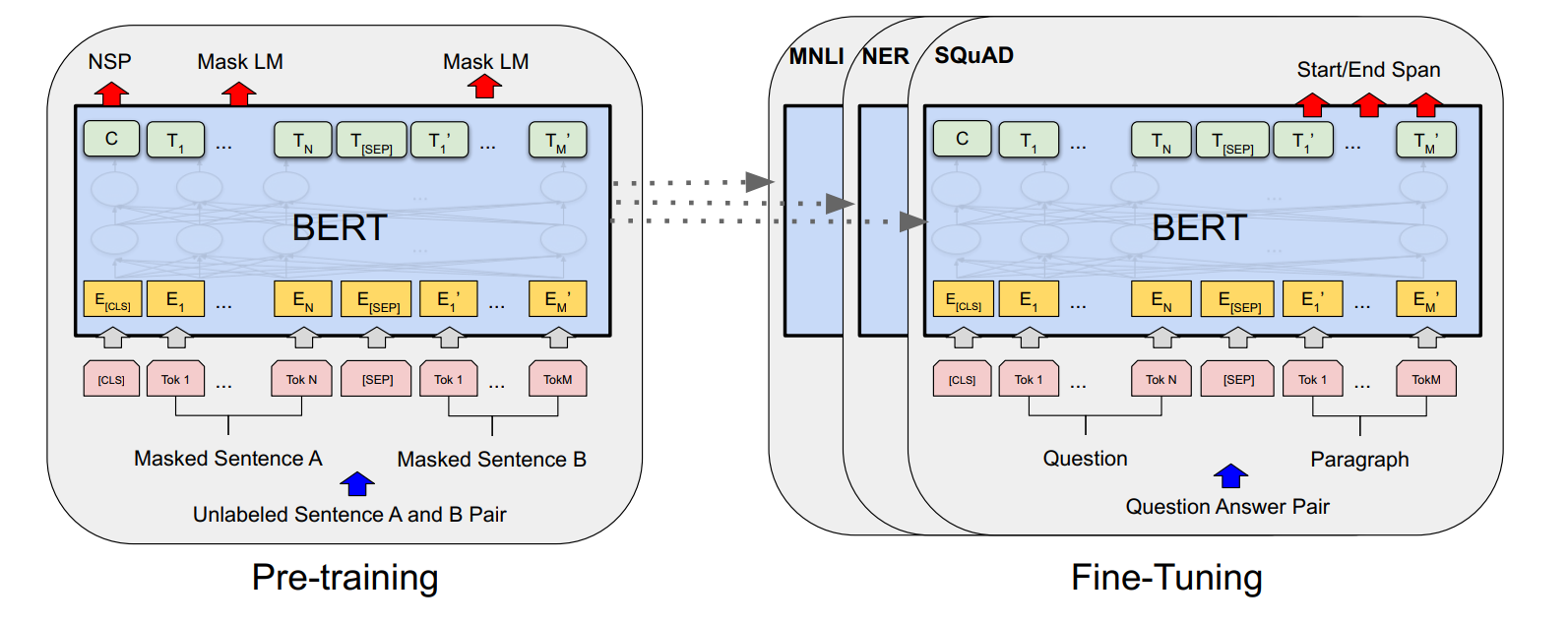
预测任务
在训练过程中,输入的文本会有一部分词(通常是 15%)被随机选择进行遮掩,并被替换为 [MASK] 标记。模型的任务是通过上下文来预测这些被 [MASK] 遮掩的词汇,即从其他未遮掩的词中学习到足够的信息来恢复原始词汇。这个任务是为了让模型学习理解单词与上下文之间的关系,帮助模型在处理下游任务时能更好地捕捉语义和语境信息。
1
2
我今天去公园散步。
我今天去 [MASK] 散步。
模型的任务是通过学习上下文(即 “我今天去” 和 “散步”)来预测 [MASK] 应该是 “公园”。
其中预测任务的表征为 [MASK] 所在位置进行预测。
模型参数
两种模型规模:BERTBASE 和 BERTLARGE。
- BERTBASE:模型包含 12 层(L=12),隐藏层维度为 768(H=768),自注意力头数为 12(A=12),总参数量为 1.1 亿(Total Parameters=110 M)。
- BERTLARGE:模型包含 24 层(L=24),隐藏层维度为 1024(H=1024),自注意力头数为 16(A=16),总参数量为 3.4 亿(Total Parameters=340 M)。
这两种模型分别代表了 BERT 的基础版本和较大规模版本,在性能和计算资源需求上有所不同。
预训练任务
Masked LM
Masked LM 缩写为 MLM。将输入的语句进行随机掩码,每个 token 都有 15% 的机率被进行掩码替换。
但微调任务中一般为:
- (1) 复述任务(Paraphrasing):句子对(两个句子是否表示相同的意思)。
- (2) 蕴含任务(Entailment):前提和假设对(假设是否能从前提推导出来)。
- (3) 问答任务(Question Answering):问题和段落对(从段落中找到问题的答案)。
- (4) 文本分类或序列标注任务:一个退化的形式,比如只有一个句子,配对的另一个句子是空的。
下游任务并不会出现 [MASK] 的 token,为了让预训练模型更具有适应性。采用了以下策略
具体做法是:随机选择 15% 的位置进行预测。
- 80% 的情况下,选择的词汇会被替换为
[MASK]。 - 10% 的情况下,选择的词汇会被替换为随机的词。
- 10% 的情况下,选择的词汇保持不变,目的是为了保持模型的表示与实际观察到的单词之间的偏向,使得模型不会完全依赖于遮蔽机制来学习表示。。
具体以 my dog is hairy 为例
- 80% 情况为
my dog is [MASK] - 10% 的情况
my dog is apple - 10% 的情况
my dog is hairy
最后,使用交叉熵损失来预测原始的词汇。这有助于模型在预训练和微调时保持一致性,并提升模型的泛化能力。
Next Sentence Prediction
Next Sentence Prediction 简称为 NSP。为了训练一个能够理解句子之间关系的模型,BERT 通过进行二元化的下一句预测任务 NSP 来进行预训练。这个任务可以很容易地从任何单语语料库中生成。许多重要的下游任务(如问答任务(QA)和自然语言推理(NLI))都依赖于理解两个句子之间的关系,而这类关系并不能通过单纯的语言模型直接捕捉到。
在 BERT 的预训练过程中,为了进行 NSP 任务,每个训练样本中的句子 A 和句子 B 有两种选择:
- 50% 的情况下,句子 B 是实际在句子 A 之后的下一句(标记为 “IsNext”)。
- 另外 50% 的情况下,句子 B 是从语料库中随机选择的句子,不是句子 A 的下一句(标记为 “NotNext”)。
通过这种方法,BERT 可以学习理解句子之间的顺序关系,从而在下游任务中更好地处理与句子间逻辑关系相关的问题。
总结
MLM(Masked Language Model)和 NSP(Next Sentence Prediction)在 BERT 的预训练过程中是同时进行的。BERT 模型在预训练时,通过一个任务同时优化这两个目标。
1
2
3
4
5
6
7
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
预训练好的 BERT 模型只需要添加一个额外的输出层,就可以进行微调,用于各种下游任务(如问答任务和语言推理),而且不需要对特定任务的模型架构进行大幅修改。
任务微调
微调的超参数设置
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 2, 3, 4
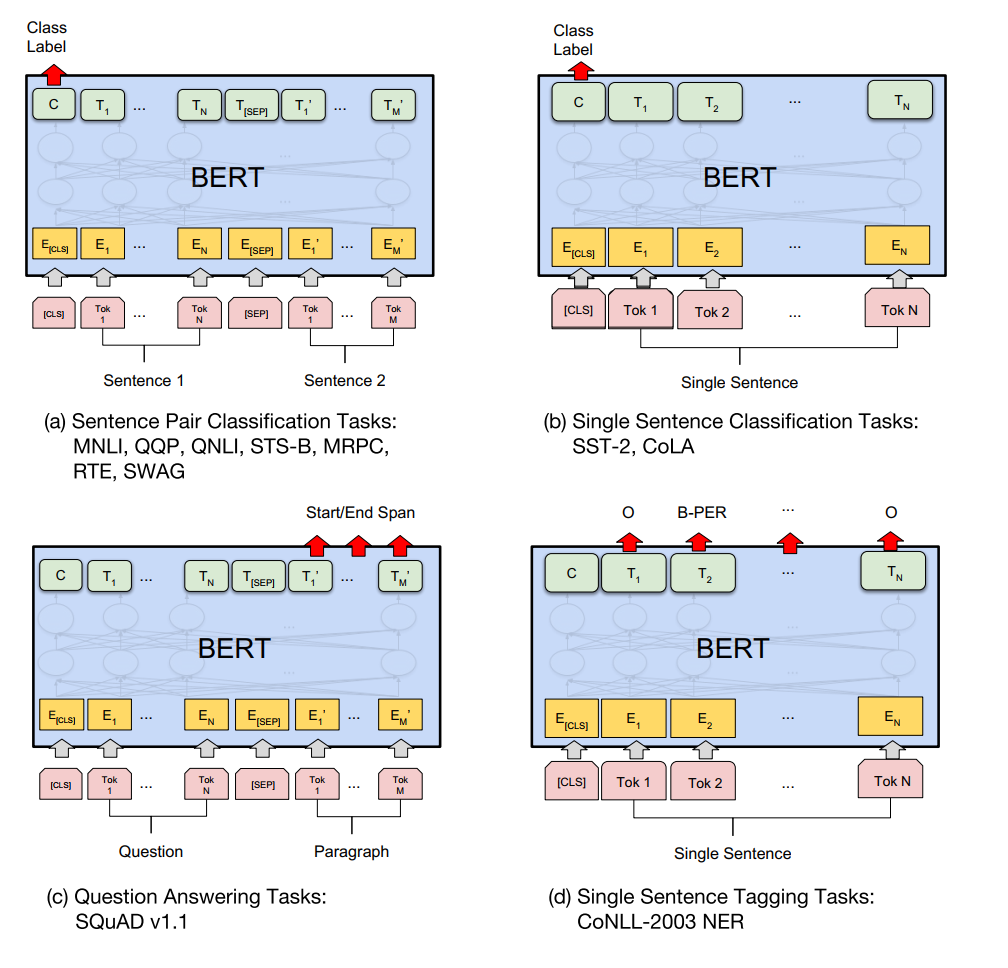
上图可以看到对 BERT 进行不同任务的微调示意图。我们的任务特定模型通过将 BERT 与一个额外的输出层结合形成,因此只需要从头学习极少量的参数。在这些任务中,(a) 和 (b) 是序列级别的任务,而 (c) 和 (d) 是词级别的任务。在图中,E 代表输入嵌入,Ti 代表第 i 个词的上下文表示,CLS 是用于分类输出的特殊符号,SEP 是用于分隔非连续词序列的特殊符号。
Question Answering
输入序列由问题和上下文(包含答案的文本)组成,它们通过特殊符号 [SEP] 分隔。
BERT 模型会输出每个词的上下文表示,模型会预测答案的起始位置和结束位置。
- 起始位置预测:BERT 的一个输出层用于预测答案的起始词在上下文中的位置。
- 结束位置预测:另一个输出层用于预测答案的结束词在上下文中的位置。
BERT QA 任务的例子:
问题:Where was Barack Obama born?
上下文:Barack Obama was born in Hawaii.
- 模型输入:
1
[CLS] Where was Barack Obama born? [SEP] Barack Obama was born in Hawaii. [SEP]
模型输出:
- 预测起始位置:词
in的位置。 - 预测结束位置:词
Hawaii的位置。
- 预测起始位置:词
最终模型会输出:in Hawaii 作为答案。
Single sentence tagging task
Single sentence tagging task 是自然语言处理(NLP)中的一种任务,它通常涉及对单个句子中的每个词进行标注。
任务特点:
- 输入:一个句子,分解为多个词或标记。
- 输出:每个词对应一个标签。
- 标签的类型:根据任务的不同,标签可能是实体类别(如人名、地点名等)、词性(如名词、动词、形容词等),或者句子结构(如名词短语、动词短语等)。
常见任务:
- 命名实体识别(NER,Named Entity Recognition):
- 任务:识别出句子中的特定实体(如人名、地点名、组织等)。
- 示例:
- 输入:
Barack Obama was born in Hawaii. - 输出:
Barack B-PER, Obama I-PER, was O, born O, in O, Hawaii B-LOC
- 输入:
- 词性标注(POS tagging):
- 任务:为句子中的每个词分配其词性(如名词、动词、形容词等)。
- 示例:
- 输入:
She enjoys reading books. - 输出:
She PRON, enjoys VERB, reading VERB, books NOUN
- 输入:
- 分块标注(Chunking):
- 任务:将句子分为不同的短语,如名词短语、动词短语等。
- 示例:
- 输入:
He reckons the current account deficit will narrow. - 输出:
He NP, reckons VP, the current account deficit NP, will VP, narrow VP
- 输入: